[AINews] DeepSeek Janus and Meta SpiRit-LM: Decoupled Image and Expressive Voice Omnimodality • ButtondownTwitterTwitter
Chapters
AI Twitter and Reddit Recaps
AI Discord Recap
Interconnects
Guest Speakers and Course Enhancements
HuggingFace NLP
LM Studio and GPU Compatibility
Mojo Development Discussions
Discussion on TinyGrad Optimization Strategies
Optimizing Tinygrad and OpenCL Integration
Adjusting GPT-4 Pricing and ColBERTv2 Training Data
AI Twitter and Reddit Recaps
This section provides recaps from Twitter and Reddit related to various AI industry updates, AI company updates, open-source developments, AI research insights, AI safety and evaluation, AI development tools, AI applications and use cases, AI community insights, and AI career updates. The highlights include discussions on new AI models, AI company launches, open-source AI collaborations, model merging techniques, AI safety measures, AI development tools, audio processing advancements, AI education applications, AI for data analysis, AI community trends, and career insights in the AI industry.
AI Discord Recap
The AI Discord Recap covers various themes discussed in different AI-related Discord channels. The summaries include topics such as model performance evaluations, advanced training techniques, cutting-edge tools and frameworks, innovative AI applications, community and collaborative efforts, and more. Each Discord channel focuses on different aspects of AI development, ranging from discussing performance challenges and fine-tuning models to exploring new tools and applications. The conversations touch on topics like language model comparisons, AI training strategies, AI ethics, societal impact, and community engagement. The summaries provide insights into the dynamic and diverse discussions happening in these AI Discord channels.
Interconnects
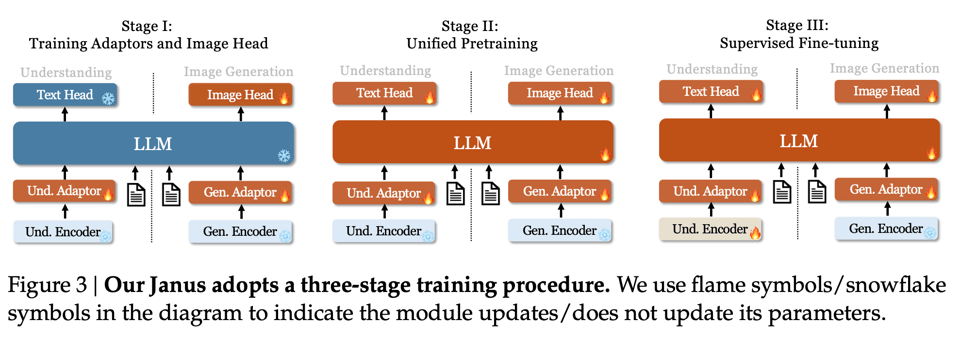
The section discusses various topics related to AI applications, including the release of the Janus project by deepseek-ai on GitHub and the search for inference providers for chat assistants. It also touches on issues like the fine-tuning context window limitation, Greg Brockman's anticipated return to OpenAI, and the importance of data quality in instruction tuning for language models. Discussions highlight aspects like potential matrix speedups with the CoLA library, concerns about tinygrad's optimization focus, challenges with OpenCL setup on Windows, and resources available to master tinygrad effectively. The community also delves into AI hackathons, creating custom checkpoints, seamless image generation difficulties, and limitations in generating specific image models due to data scarcity. Sampling methods for generating cartoon styles and addressing image training challenges are also explored.
Guest Speakers and Course Enhancements
This section discusses the involvement of guest speakers like Denny Zhou, Shunyu Yao, and Chi Wang in the course to provide valuable insights and enhance the learning experience with real-world perspectives. Participants are eagerly anticipating these sessions as they could bridge the gap between theory and application. Additionally, there are discussions on various topics such as feedback on article assignments, community collaboration in refining submissions, and the importance of leveraging the community for feedback on written assignments. The section highlights the engagement and anticipation within the community for the upcoming guest appearances and collaborative efforts to ensure quality and effective participation in live discussions.
HuggingFace NLP
Perplexity Transforms Financial Research:
Perplexity now offers a feature for finance enthusiasts that includes real-time stock quotes, historical earning reports, and industry peer comparisons, all presented with a delightful UI. Members are encouraged to have fun researching the market using this new tool. Market Analysis Made Easy: The new finance feature allows users to perform detailed analysis of company financials effortlessly, enhancing the stock research experience. This tool promises to be a game changer for those interested in keeping up with financial trends.
Behavioral Economics and Decision-Making Insights: A complex query on behavioral economics explored how cognitive biases influence decision-making in high-stress environments, particularly during financial crises. Key points discussed included loss aversion and its effects on expected utility models, indicating a significant alteration in rational behavior.
Examining Fine-Tuning and Model Merging: A member shared a paper titled Tracking Universal Features Through Fine-Tuning and Model Merging, investigating how features persist through model adaptations. The study focuses on a base Transformer model fine-tuned on various domains and examines the evolution of features across different language applications.
Discussion on Mimicking Models: Feedback was given regarding the limitations of mimicking large language models, emphasizing that many lack the comprehensive datasets like those used by larger models. The conversation highlighted the challenges and similarities in their approaches to model adaptation and feature extraction.
Links mentioned:
- Paper page - Tracking Universal Features Through Fine-Tuning and Model Merging: no description found
- GitHub - rbourgeat/airay: A simple AI detector (Image & Text): A simple AI detector (Image & Text). Contribute to rbourgeat/airay development by creating an account on GitHub.
- starsnatched/thinker · Datasets at Hugging Face: no description found
- starsnatched/ThinkerGemma · Hugging Face: no description found
LM Studio and GPU Compatibility
Discussions in the LM Studio ▷ #general channel involved various topics related to LM Studio and GPU compatibility. Users shared their experiences with issues like LM Studio Auto Scroll, ROCM compatibility with AMD GPUs, performance of different language models, introduction to the Agent Zero AI Framework, and memory management concerns in MLX-LM. Links mentioned in the discussion included resources on running language models on AMD Ryzen AI PCs, a GitHub pull request addressing memory issues, and more. The conversations highlighted user experiences, inquiries, and potential solutions to optimize GPU utilization and performance in language model operations.
Mojo Development Discussions
In this section, discussions around Mojo development were highlighted. Emphasis was placed on package management, the absence of a native matrix type, and the need for comprehensive documentation for tensors. Mojo aims at performance improvement to attract users familiar with libraries like NumPy and TensorFlow, while maintaining 'zero overhead abstractions' and aiming for a Pythonic experience. Issues concerning Tensor implementation in Mojo were addressed, along with community engagement calls for feedback and usability enhancements. The importance of foundational libraries before broader Python community integration was underscored, with comparisons drawn between Mojo's relationship with Python and TypeScript's approach. The section also featured links to Mojo's programming language page and a community Q&A form.
Discussion on TinyGrad Optimization Strategies
A member inquired about projects similar to llama2.c but specifically for diffusion projects implemented in pure C. Another member directed the inquiry to stable-diffusion.cpp, designed for Stable Diffusion and Flux in pure C/C++. However, it was noted that this project is built on GGML, which does not meet the original request. Members discussed that implementing the whole project in pure C would likely lead to using many of the same GGML abstractions. As one remarked, 'It’s just a machine learning library in pure C, lol.'
Optimizing Tinygrad and OpenCL Integration
During this section, the discussion revolved around improving the performance of tasks like eigenvalue calculations and matrix inversions in Tinygrad by considering the use of decomposed matrices. There were deliberations on whether focusing on dense matrix optimization over 'composed' matrix operations would be a better strategy. While facing challenges such as CI errors with OpenCL on Windows, the importance of setting up OpenCL for testing was emphasized to ensure smooth functioning, especially when involving GPUs. The need to install necessary dependencies on the CI machine for proper OpenCL testing was also acknowledged.
Adjusting GPT-4 Pricing and ColBERTv2 Training Data
The cost of using GPT-4 has decreased to $2.5 per million input tokens and $10 per million output tokens, marking a significant reduction from its initial pricing. Members discussed confusion regarding ColBERTv2 training data using n-way tuples with scores. Recommendations were made for adjusting positive and negative document scores and implementing PATH with cross-encoders like DeBERTa and MiniLM. The use of pylate for training colbert-small-v1 was also suggested, sparking interest among members to explore this further.
FAQ
Q: What is the Perplexity feature offered by Perplexity for finance enthusiasts?
A: The Perplexity feature offers real-time stock quotes, historical earning reports, and industry peer comparisons, all presented with a delightful UI. It aims to enhance the stock research experience and make market analysis easy for users interested in financial trends.
Q: What were some key points discussed regarding cognitive biases in decision-making during high-stress environments?
A: The discussions explored how cognitive biases, particularly loss aversion, influence decision-making in high-stress environments such as financial crises. This included how loss aversion affects expected utility models and leads to significant alterations in rational behavior.
Q: What was the focus of the paper 'Tracking Universal Features Through Fine-Tuning and Model Merging' shared by a member?
A: The paper investigates how features persist through model adaptations by fine-tuning a base Transformer model on various domains. It examines the evolution of features across different language applications and discusses the process of model merging.
Q: What were the limitations highlighted in the discussions about mimicking large language models?
A: The conversations emphasized that many models lack comprehensive datasets like those used by larger models, posing challenges in mimicking their behavior effectively. The discussions also highlighted similarities in approaches to model adaptation and feature extraction.
Q: What were some of the topics discussed in the LM Studio Discord channel related to LM Studio and GPU compatibility?
A: The discussions involved topics such as LM Studio Auto Scroll, ROCM compatibility with AMD GPUs, performance of different language models, introduction to the Agent Zero AI Framework, and memory management concerns in MLX-LM. Users also shared resources related to running language models on AMD Ryzen AI PCs and addressing memory issues via GitHub pull requests.
Q: What was the focus of the discussions regarding Mojo development and its relation to Python?
A: The discussions highlighted emphasis on package management, the absence of a native matrix type, and the need for comprehensive documentation for tensors in Mojo development. Mojo aims at performance improvement while maintaining 'zero overhead abstractions' and a Pythonic experience. User feedback and community engagement were underscored for usability enhancements.
Q: What was the inquiry made by a member regarding diffusion projects implemented in pure C?
A: A member inquired about projects similar to llama2.c specifically for diffusion projects implemented in pure C. The discussion directed the member to stable-diffusion.cpp for Stable Diffusion and Flux in pure C/C++, though noting that it is built on GGML and may not fully meet the original request.
Q: What was the focus of the discussions regarding improving the performance of tasks like eigenvalue calculations and matrix inversions in Tinygrad?
A: The discussions revolved around considering the use of decomposed matrices to improve the performance of tasks like eigenvalue calculations and matrix inversions in Tinygrad. Emphasis was placed on setting up OpenCL for testing to ensure smooth functioning, especially with GPUs.
Q: What was the reduction in cost for using GPT-4 discussed in the sections?
A: The cost of using GPT-4 decreased to $2.5 per million input tokens and $10 per million output tokens, marking a significant reduction from its initial pricing. This reduction sparked discussions among members regarding the training data used by ColBERTv2 and recommendations for adjusting scores and implementing PATH with cross-encoders.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!