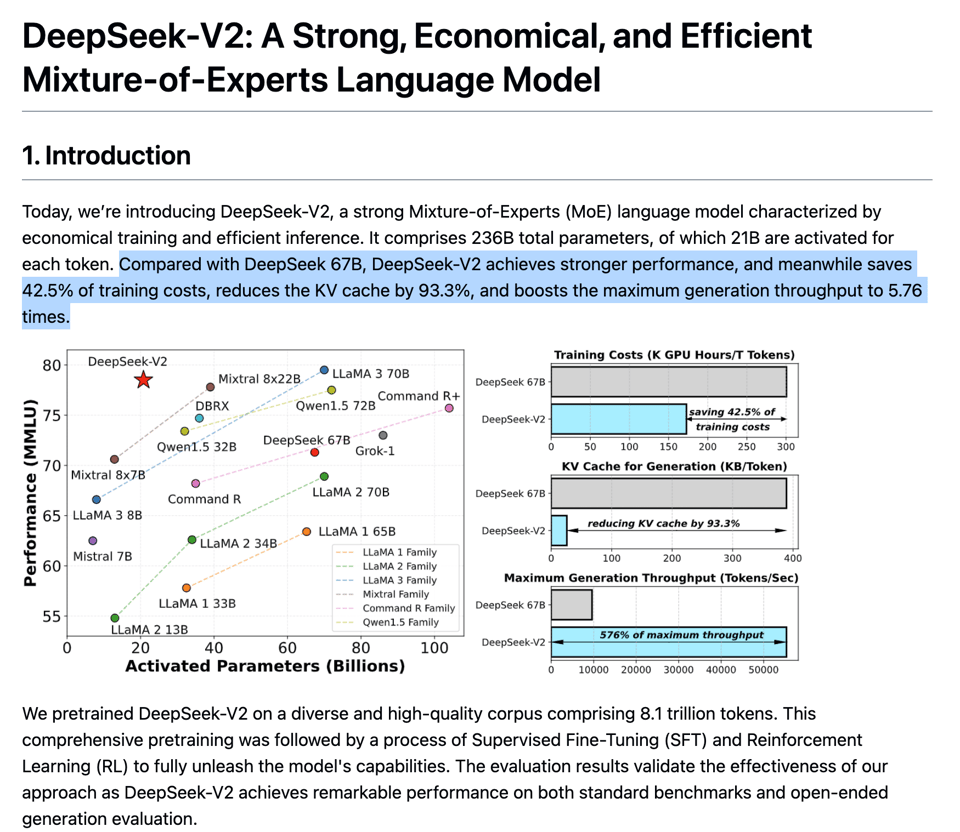
[AINews] DeepSeek-V2 beats Mixtral 8x22B with >160 experts at HALF the cost • ButtondownTwitterTwitter
Chapters
AI Discord Recap
Stability.ai (Stable Diffusion)
Open Interpreter Discord
Discord AI Community Updates
Unsloth AI Discussions
Discussion on Various AI-related Topics
World-sim Discussions and Updates
Exploring Perplexity's Rich History, BASIC Language Information, and AI Discoveries
LM Studio: Autogen Chat
Upcoming Recording for Cuda NCCL
Discord Conversations on JAX, GreenBitAI, and Modular (Mojo) 🔥
NuMojo Update and Other Community Projects
Exciting Community Projects and AI Conversations
Graph ML and LLMs Discussion
AI Vtubers and Stream Interaction
Latest Projects and Community Discussions on OpenRouter, LlamaIndex, and Axolotl
Inference and Other Discussions
LAION, LangChain, and StoryDiffusion Discussions
Conversation Highlights on AI Discord Channels
AI Discord Recap
AI Discord Recap
A summary of Summaries of Summaries
-
Llama3 GGUF Conversion Challenges: Users encountered issues converting Llama3 models to GGUF format using llama.cpp, with training data loss unrelated to precision. Regex mismatches for new lines were identified as a potential cause, impacting platforms like ollama and lm studio. Community members are collaborating on fixes like regex modifications.
-
GPT-4 Turbo Performance Concerns: OpenAI users reported significant latency increases and confusion over message cap thresholds for GPT-4 Turbo, with some experiencing 5-10x slower response times and caps between 25-50 messages. Theories include dynamic adjustments during peak usage.
-
Stable Diffusion Installation Woes: Stability.ai community
Stability.ai (Stable Diffusion)
Members sought help with Stable Diffusion setups failing to access GPU resources and encountering errors like "RuntimeError: Torch is not able to use GPU". Discussions also covered the lack of comprehensive, up-to-date LoRA/DreamBooth/fine-tuning tutorials. Anticipation surrounded the release of Stable Diffusion 3, with debates on potential delays and skepticism. The community expressed frustration over the shortage of tutorials for techniques like LoRA/DreamBooth/fine-tuning. Additionally, discussions touched on training AI for generating unique faces, open-source commitments, and the authenticity of Stable Diffusion's models.
Open Interpreter Discord
Engineers are discussing challenges with integrating Groq LLM onto Open Interpreter, facing issues like uncontrollable output and erroneous file creation. A Microsoft Hackathon seeks enthusiasts to utilize Open Interpreter, offering hands-on tutorials. Discussions revolve around reimplementation of TMC protocol for iOS on Open Interpreter. Personal testings on local LLMs reveal significant performance variances. Implementing Speech-to-Text for AI virtual streamers brings up practical challenges, aiming for comprehensive responses through AI-driven Twitch chat interactions and sharing resources like a main.py file on GitHub.
Discord AI Community Updates
This section provides updates on recent discussions and developments in various Discord channels related to AI. Topics include AI voice cloning technology, a new language model evaluator, discussions on classical reinforcement learning, and humorous anecdotes shared among community members. Additionally, information about new AI tools, model performance challenges, and opportunities for AI projects and research grants are highlighted.
Unsloth AI Discussions
Proposal for Model Size Discussion Channel: A user suggests creating a channel on Unsloth Discord to discuss successes and strategies in deploying large language models (LLMs), emphasizing the value of sharing experiences for collective learning.### Push for Llama-3-8B-Based Projects: RomboDawg announces a new coding model enhancing Llama-3-8B-Instruct, competes with Llama-3-70B-Instruct, and plans to release version 2 in about three days.### Knowledge Graph LLM Variant Released: M.chimiste introduces Llama-3-8B-RDF-Experiment to assist in knowledge graph construction and genomic data training.### Creptographic Collaborations on the Horizon: One user seeks advice and collaboration to integrate cryptographic elements into blockchain technologies.### AI-Enhanced Web Development Tools Theme: Oncord integrates Unsloth AI for LLM fine-tuning to provide code completions, showcasing a modern web development platform with marketing and commerce tools.
Discussion on Various AI-related Topics
The section discusses a wide range of AI-related topics from different Discord channels. Issues in project management, deletion, and navigability are highlighted in a new feature of a particular AI project. Users express skepticism about the release of GPT-5 due to diminishing returns. Strategies for improving ChatGPT's knowledge base search capabilities are debated. Members share insights on fine-tuning AI models for questioning, successful bot designs, and pitfalls of using negative prompts. Recommendations for books and resources on prompt engineering are also discussed. Additionally, users seek assistance in refining prompts, discuss logit bias in token suppression, and explore various AI model enhancements and limitations.
World-sim Discussions and Updates
Members of the Nous Research AI community engage in various discussions related to world-sim projects, philosophical grounding in AI, cosmic-scale world-building concepts, ethical considerations in simulations, and sharing world-sim projects and volunteer sign-ups. These discussions cover topics such as anticipation for new world-sim versions, philosophical debates on AI, extensive narrative layers in projects, ethical concerns in simulation creation, and sharing of related projects and volunteer opportunities.
Exploring Perplexity's Rich History, BASIC Language Information, and AI Discoveries
This section delves into the community's exploration of Perplexity's rich history, including links to delve into the depths of the company's past. Members also shared insights into the origins and details of the BASIC programming language. An AI revelation of 27,000 unknown items sparked curiosity. Additionally, Perplexity's features were highlighted in a Forbes video. Members used creative search queries to prompt AI exploration, showcasing the platform's capabilities.
LM Studio: Autogen Chat
In the LM Studio Autogen chat, a member raised concerns about the LM Studio API speech limitation limiting it to two words. This member sought technical insights into the issue. Another message mentioned secrets not making friends in the LMC Studio Langchain chat. This section highlighted discussions on improving the LM Studio server activation and operation using the lms CLI. The release of CodeGemma 1.1 in the model announcements chat sparked anticipation for performance upgrades. Nvidia's release of ChatQA 1.5 models tailored for context-based Q/A was also noted. Overall, these conversations aim to optimize user experience and performance within the LM Studio environment.
Upcoming Recording for Cuda NCCL
Members of the CUDA MODE Discord channel discussed various topics related to CUDA, PyTorch, and machine learning. In one thread, they shared information about the upcoming recording of the NCCL session, including updates on new fused DoRA kernels, potential optimizations for DoRA weights, and interest in in-depth benchmarking. Additionally, members sought help on installing custom PyTorch/CUDA extensions, TorchServe GPU configuration, atomic operations in CUDA, and performance comparison between Numba-CUDA and CUDA-C. The section also highlighted discussions on special techniques like CUTLASS and Stream-K scheduling, along with tools like HTA for holistic trace analysis in PyTorch. Furthermore, links to helpful resources like Answer.AI's open-source system and papers on ML systems and quantization were shared among the community.
Discord Conversations on JAX, GreenBitAI, and Modular (Mojo) 🔥
The discussions in this section cover a range of topics related to JAX processes, GreenBitAI's LLM toolkit, and contributions to the Modular (Mojo) environment. Members shared their anime favorites, discussed using iPhone & Mac for enhanced A/V setup, and expressed interest in Discord to Google Calendar automation. GreenBitAI's binary matrix multiplication and calculation of gradients in weights were also highlighted. In another Discord channel, conversations revolved around resolving compilation issues and improving performance in multi-GPU training. The Mojo community discussed installation queries, community progression, contributions to the Mojo standard library, and the versioning scheme used by Mojo.
NuMojo Update and Other Community Projects
The section discusses the NuMojo library, updated to Mojo version 24.3, offering a significant performance boost compared to numpy. It also introduces Mimage, a library for image parsing in Mojo. Additionally, progress on the Basalt project, including experimental ONNX model import/export in Mojo 24.3, is highlighted. Discussions on struct composability in Mojo, a Mojo port of the minbpe project, and positive community feedback on various blog posts and tutorials are covered.
Exciting Community Projects and AI Conversations
Exploring Audio Diffusion Modelling: A model that generates music iteratively based on feedback was discussed. Computational depth and the model's ability to create longer and theoretically sound pieces were highlighted.
Struggling with large model conversion: Difficulties in converting a PyTorch model to TensorFlow Lite due to size limit errors were shared.
Deploying Whisper for Filipino ASR: Feasibility of fine-tuning the Whisper ASR model for Filipino language was discussed, mentioning factors like weight decay, learning rate, and dataset size.
Security Concerns After Hacks: Discussions around the compromised Hugging Face Twitter account led to cybersecurity measures considerations and their impact on AI systems.
GPU Utilization Mysteries: Variances in GPU training times between local machines and Google Colab were explored, focusing on consumer gaming cards and edge inference cards' efficiency differences and optimization tips.
Graph ML and LLMs Discussion
The HuggingFace Discord group is engaging in a meeting focused on a recent paper about Graph Machine Learning, exploring the use of Large Language Models (LLMs) in graph machine learning and its wide applications. Members are also discussing the versatility of Graph Neural Networks (GNNs) for various tasks like fraud detection, recommendation generation, and task planning for robots. Moreover, there is resource sharing by presenter Isamu Isozaki in the form of a medium article and a YouTube video exploring the topic further. Additionally, there is a conversation about the integration of special tokens in LLMs to trigger information retrieval when uncertain, aiming to enhance accuracy and efficiency by retrieving information only when necessary.
AI Vtubers and Stream Interaction
- STT Challenges for AI Vtubers: Implementing Speech-to-Text (STT) for AI Vtubers faced challenges with live transcription.
- Encouraging AI Interaction with Stream Audiences: AI Vtubers interact with audiences via Twitch, exploring sustained engagement methods.
- AI Managed Twitch Chat Interactions Plan: Establishing a chatbot for Twitch interactions to engage audiences effectively.
- Control Over LLM Behavior Through Prompts: Using Instruct models to control language model outcomes.
- Sharing Practical AI Integration Code: Sharing GitHub code for chatbot integration.
Latest Projects and Community Discussions on OpenRouter, LlamaIndex, and Axolotl
The latest community activities include the introduction of new AI projects on OpenRouter. Notable projects include eGirlfriend AI, a family-friendly chat app called Family Chat, and Rubik's AI Pro seeking beta testers. The LlamaIndex community discusses advancements such as introspective agents, agentic RAG, and trust assessments in RAG responses. Axolotl's community delves into topics like Gradio configurations, deep dives into token troubles, and dynamic Gradio parameters. Additionally, the community addresses the eternal question of opening issues versus submitting pull requests.
Inference and Other Discussions
Inference on Trained Llama3: There were queries on calling inference after training llama3 with the fft script. Tuning Inference Parameters: Using a parameter setting of 4,4 was recommended as effective for an unspecified context. Conversion of Safetensors to GGUF: Assistance was sought in converting safetensors to gguf with more options than provided by llama.cpp, mentioning formats like Q4_K and Q5_K. Script for Llama.cpp Conversions: Users were directed to llama.cpp's conversion scripts, particularly highlighting convert-gg.sh for dealing with gguf conversion options. Axolotl Community Documentation: A link to the Axolotl community documentation was shared, requiring more work on merging model weights post-training and using the model for inference. OpenAccess AI Collective: The CodeTester Dataset Expansion featured an updated Python dataset with carefully tested code examples. Tough Time Training Llama3 on Math: Challenges in improving model performance on mathematical content with Llama3 despite training on datasets like orca-math-word-problems-200k and MetaMathQA were discussed. Impact of Quantization on Model Performance: Negative impact of llama.cpp quantization on model performance was highlighted. Evaluation Scripts and Prompting: Discussions on using lm-evaluation-harness for inference and evaluation of Llama3, emphasizing the importance of correct prompt format. Prompt Format Puzzles: Ongoing debate on how the prompt format during finetuning might affect model performance, especially with Alpaca format prompts.
LAION, LangChain, and StoryDiffusion Discussions
Exploration of CLIP and T5 Combination:
- Discussions on using CLIP and T5 encoders for model training, highlighting different member perspectives.
- Considerations for Improving Smaller Models focusing on practicality and challenges with model releases.
- Skeptical Reception of SD3 Strategy: Gradual release of SD3 models debated in the community.
- Potential Use of LLama Embeds in Training discussed with a link to LaVi-Bridge for efficiency.
- Comparative Progress in Image Gen and LLM Spaces: Comparison of open-source models discussed, mentioning new CogVL marquee.
Real-World vs Synthetic Datasets Query:
- Curiosity on synthetic dataset usage for experiments and interpretability concerns.
- Interpretability Demonstrations using synthetic datasets discussed.
- StoryDiffusion Resource Shared: Link to StoryDiffusion website shared for interpretability resources.
- Complexity Over Simplicity in Function Representation: Research focus on approximating complex representations with functions discussed.
Database Interfacing with LLMs Sparks Curiosity:
- Debates on database data conversion and LLM usage for queries discussed.
- Node.JS Conundrums and First Steps with Langchain: Users seek and provide assistance with NodeJS and Langchain.
- Executing through Code with AI: Insights on executing generated code through AI agents shared.
- Langchain Integration Queries: Inquiries about Microsoft Graph support, Langchain tools, and upload size limits discussed.
- New Developments and Custom Tools Discussed: Speculations on ChatGPT responses, creating custom tools, and sharing within the Langchain community discussed.
Conversation Highlights on AI Discord Channels
This section provides highlights from various conversations on different AI Discord channels. It includes discussions on current AI models in use, advancements in AI voice cloning technology by ElevenLabs, new language models like Prometheus 2, challenges in classical RL research, tools for error evaluation using LLM, AI platform for R&D funding opportunities, and AI21 Labs exploring new technological heights. Members also share experiences with fast compute grants and engage in discussions on various AI-related topics.
FAQ
Q: What challenges were encountered in converting Llama3 models to GGUF format?
A: Users encountered issues converting Llama3 models to GGUF format, with training data loss unrelated to precision. Regex mismatches for new lines were identified as a potential cause.
Q: What performance concerns were reported by OpenAI users regarding GPT-4 Turbo?
A: OpenAI users reported significant latency increases and confusion over message cap thresholds for GPT-4 Turbo, with some experiencing 5-10x slower response times and caps between 25-50 messages.
Q: What were the stability issues faced by the Stability.ai community related to Stable Diffusion setups?
A: Members sought help with Stable Diffusion setups failing to access GPU resources and encountering errors like 'RuntimeError: Torch is not able to use GPU'.
Q: What challenges were faced in integrating Groq LLM onto Open Interpreter according to engineers?
A: Engineers discussed challenges with integrating Groq LLM onto Open Interpreter, facing issues like uncontrollable output and erroneous file creation.
Q: What practical challenges were discussed regarding implementing Speech-to-Text for AI virtual streamers?
A: Discussions mentioned practical challenges in implementing Speech-to-Text for AI virtual streamers, aiming for comprehensive responses through AI-driven Twitch chat interactions and sharing resources like a main.py file on GitHub.
Q: What were some of the topics discussed in the Nous Research AI community?
A: Members engaged in discussions related to world-sim projects, philosophical grounding in AI, cosmic-scale world-building concepts, ethical considerations in simulations, and sharing world-sim projects and volunteer sign-ups.
Q: What were the key highlights of discussions in the HuggingFace Discord group regarding Large Language Models (LLMs) in graph machine learning?
A: Discussions focused on the use of Large Language Models (LLMs) in graph machine learning, the versatility of Graph Neural Networks (GNNs) for tasks like fraud detection, recommendation generation, and task planning for robots.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!