[AINews] Llama-3-70b is GPT-4-level Open Model • ButtondownTwitterTwitter
Chapters
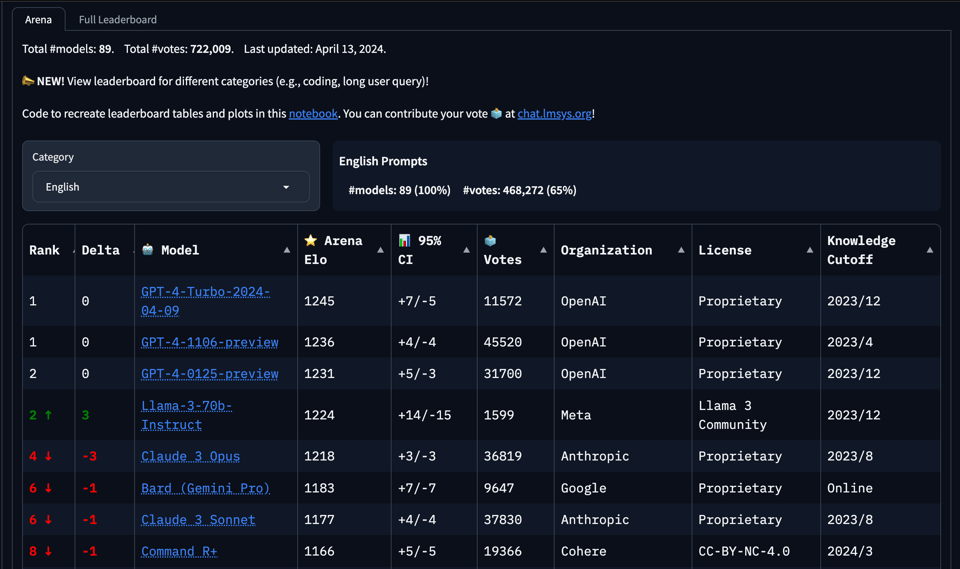
Llama-3-70b is GPT-4-level Open Model
High Level Discord Summaries
Interconnects (Nathan Lambert)
LLM Perf Enthusiasts AI Discord
Unsloth AI Updates
LM Studio Features and Model Discussions
Discussion on Llama 3 in Nous Research AI
CUDA Mode Discussions
Issues and Updates on Llama-3 Model
Latent Space Pod Drops New Episode
Discussions on Scaling Laws, Mechanistic Interpretability Updates, and Model Evaluations
HuggingFace Discussions Highlights
User Concerns and Discussions around GPT-4 Turbo and Assistant APIs
Discussion on New Language Models and Tools
LangChain AI Forum Discussions
Skunkworks AI ▷ #finetuning
Llama-3-70b is GPT-4-level Open Model
AI Reddit Recap
- Across various AI-related subreddits, comment crawling has been showing progress, though there are areas for improvement.
Meta's Llama 3 Release and Capabilities
- Meta released Llama 3, which includes models with 8B and 70B parameters. The 70B model outperforms previous models like Llama 2, and the 70B model provides GPT-4 level performance at significantly lower cost. Llama 3 also excels in tasks like function calling and arithmetic. Microsoft and Meta introduced lifelike talking face generation and impressive video AI, while Stable Diffusion 3 faced some critique over its capabilities.
AI Scaling Challenges and Compute Requirements
- Discussions point to the rapid increase in AI's energy usage and GPU demand, with talks of AI's computing power needs potentially overwhelming energy sources by 2030, and the immense GPUs required for training future models.
AI Safety, Bias, and Societal Impact Discussions
- Debates on political bias in AI models and discussions on AI's potential to break encryption. There's also talk about AI doomerism versus optimism for beneficial AI development.
AI Twitter Recap
- Meta Llama 3 Release: Details about the Llama 3 models, their performance benchmarks, and availability across various platforms were highlighted. The significance of Llama 3 in the open-source AI landscape, computational trends, and future implications were discussed.
AI Discord Recap
- Meta's Llama 3 Release Sparks Excitement and Debate: Meta introduced Llama 3 models with different parameters, sparking discussions on their performance benchmarks and licensing restrictions. Anticipation for the 405B parameter Llama 3 model was high.
- Mixtral Raises the Bar for Open-Source AI: Mistral AI's Mixtral model was praised for setting new standards, and technical challenges during its training were discussed.
- Efficient Inference and Model Compression Gain Traction: Various quantization techniques and tools aimed at improving inference efficiency were shared.
- Open-Source Tooling and Applications Flourish: Projects like LlamaIndex and LangChain's prompt engineering course were highlighted.
High Level Discord Summaries
Discussions in various AI Discord servers are centered around recent advancements and challenges in the field of artificial intelligence. Key topics include the performance and integration of the Llama 3 model, comparative benchmarks with other leading models, hardware compatibility, and innovative strategies for AI model training and application. Users in these communities actively engage in troubleshooting, sharing insights, and proposing future developments in the AI landscape. Some specific highlights include advancements in language modeling, debates on AI art models, challenges with training AI models on specific hardware configurations, and community efforts towards optimizing AI model performance and efficiency.
Interconnects (Nathan Lambert)
Excitement is building around PPO-MCTS, a cutting-edge decoding algorithm that combines Monte Carlo Tree Search with Proximal Policy Optimization, providing more preferable text generation. Discussions heated over Meta's Llama 3, a series of new large language models up to 70 billion parameters, with particular attention to the possible disruptiveness of an upcoming 405 billion parameter model. Anticipation around the LLaMa3 release influenced presenters' slide preparations, with some needing to potentially include last-minute updates to their materials. In light of the LLaMa3 discussion, presenters geared up to address questions during their talks, while concurrently prioritizing blog post writing. There's eagerness from the community for the release of a presentation recording, highlighting the interest in recent discussions and progress in AI fields.
LLM Perf Enthusiasts AI Discord
- Curiosity around litellm: A member inquired about the application of litellm within the community, signaling interest in usage patterns or case studies involving this tool.
- Llama 3 Leads the Charge: Claims have surfaced of Llama 3's superior capability over opus, particularly highlighting its performance in an unnamed arena at a scale of 70b.
- Style or Substance?: A conversation sparked concerning whether performance discrepancies are a result of stylistic differences or a true variance in intelligence.
- Warning on Error Bounds: Error bounds became a focal point as a member raised concerns, possibly warning other members to proceed with caution when interpreting data or models.
- Humor Break with a Tumble: In a lighter moment, a member shared a gif depicting comic relief through an animated fall.
Unsloth AI Updates
- Llama 3 Hits the Ground Running: Double the training speed and 60% reduction in memory usage promised.
- Freely Accessible Llama Notebooks: Users can now access free notebooks for Llama 3 on Colab and Kaggle.
- Innovating with 4-bit Models: Unsloth launches 4-bit models of Llama-3 for efficiency.
- Experimentation Encouraged by Unsloth: The community is encouraged to share, test, and discuss outcomes using Unsloth AI's models.
LM Studio Features and Model Discussions
Discussions in the LM Studio channels cover a range of topics related to the LM Studio features, Llama 3 models, and community interactions. Users are exploring the capabilities of Llama 3 models, comparing them to previous versions and other AI models. There are queries about download and runtime concerns, prompt settings, and upcoming model releases. LM Studio introduces Llama 3 support in the latest update, while users highlight the efficiency and performance of various Llama 3 models. Additionally, community feedback is shared regarding model sorting, text-to-speech integration, bug reports, and hardware compatibility. The channels also involve discussions on prompt configurations, Git cloning strategies, and TheBloke's Discord server access. Noteworthy mentions include the availability of Llama 3 models, compatibility issues with certain GPUs, and efforts to enhance long context inference using multiple GPUs.
Discussion on Llama 3 in Nous Research AI
This section delves into various discussions related to Llama 3 in the Nous Research AI community. Users explore the performance and limitations of Llama 3, comparing it with models like Mistral. Issues such as context limitations and chat generation are addressed, along with the licensing terms of Llama 3. Additionally, the community evaluates GGUF quantized models, discusses the implications of model restrictions, and shares insights on training multiple models simultaneously. The section provides a glimpse into ongoing research and community interactions surrounding Llama 3.
CUDA Mode Discussions
Discussions in the CUDA Mode channel cover a wide range of topics related to optimizing CUDA code for GPU efficiency and performance. Members share insights and experiences on topics such as matrix tiling, CUDA kernels, quantization, memory access patterns, and multi-GPU training. Specific discussions include the efficiency benefits of tiling matrix multiplication, strategic tiling tactics for optimal matrix handling, Meta's Llama 3 developments, new model capabilities with Llama models, and troubleshooting custom kernel issues in torch. The conversations explore various aspects of CUDA programming, from learning prerequisites and resources for beginners to advanced optimization techniques like integer divisions for performance improvements. The community also delves into specific implementations like Half-Quadratic Quantization (HQQ) and fused classifier kernels, aiming to enhance GPU computing capabilities for AI and deep learning applications.
Issues and Updates on Llama-3 Model
Llama-3 Launch and Performance
- Users discuss the launch of Meta Llama 3, its tokenizer efficiency, and the need for longer context versions.
- Mixed feelings on Llama 3 performance, especially concerning initial loss rates and slow loss improvement during finetuning.
Technical Challenges
- Users face issues merging qlora adapter into Llama 3 and report errors with tokenizer loading and unexpected keyword arguments during finetuning.
- AMD GPU users seek support and explore memory-efficient attention benefits.
- ChatML and tokenizer configurations present challenges for users, who share attempts and fixes for mapping special tokens correctly.
Latent Space Pod Drops New Episode
The Latent Space Discord community shares a new podcast episode featuring @199392275124453376. Member <strong>mitchellbwright</strong> expresses excitement for the latest podcast installment featuring <strong>Jason Liu</strong>.
Discussions on Scaling Laws, Mechanistic Interpretability Updates, and Model Evaluations
Discussions on Scaling Laws
- Some discussions revolved around the scaling laws related to Chinchilla's methods, where corrections were made to the third method to align it better with other approaches.
- Members debated the reliability of the third method and the implications of a replication attempt of the Chinchilla study.
- Discoveries were made regarding potential easter eggs in arXiv papers, emphasizing the ability to download the TeX source for additional insights.
Mechanistic Interpretability Updates
- Google DeepMind's progress update on Sparse Autoencoders (SAEs) was shared, highlighting advancements in interpreting steering vectors, sparse approximation algorithms, ghost gradients, and working with larger models and JAX.
- Neel Nanda's tweet reflecting on the update was mentioned.
Model Evaluations and Contributions
- Members discussed improvements in language generation speed using vLLM, pull requests for multilingual evaluation benchmarks, and seeking guidance for lm-evaluation-harness unit tests.
- There were talks about presenting the MMLU benchmark similarly to ARC, clarifying loglikelihood calculations, and enhancing prompt engineering techniques.
HuggingFace Discussions Highlights
The HuggingFace discussions spanned various topics about HuggingFace models and tools. Members shared experiences, inquiries, and insights related to models like LLaMA 3 and Mixtral, seeking troubleshooting advice and best practices. Additionally, there were discussions on AI model performance, generating synthetic data with Blender, and exploring insights on loss functions like PyTorch's BCEWithLogitsLoss. The community also delved into the challenges of running large models on consumer hardware and exchanges on mastering AI tools like DALL-E 3.
User Concerns and Discussions around GPT-4 Turbo and Assistant APIs
User Concerns
- A user expressed disappointment with the performance of gpt-4-turbo (non-preview, the 0409 one) compared to the previous 0125 preview version for their assistant application.
- Issues were raised about the Assistant API where the system waits for the function result before displaying a loading message. A UI workaround was suggested to manage the visibility of loading messages dynamically.
- Integration of GPT-4 with Claude 3 Opus was discussed, where GPT-4 first responds, then queries the Claude model and combines both responses. However, an error was reported when trying the service at the provided link.
OpenAI ▷ #prompt-engineering (30 messages🔥)
- Frustration over code integration issues where a member had to manually complete the integration.
- Discussion on ChatGPT's reduced performance post Elon Musk's lawsuit with speculations on deliberate quality reduction.
- Advice against using PDFs to provide rules to an AI assistant and encouraged the use of plain text or structured formats like XML or JSON.
- Inquiry on prompt engineering best practices and challenges faced in JSON data summarization.
- A member looking to integrate AI with blockchain technology sought collaboration.
OpenAI ▷ #api-discussions (30 messages🔥)
- Dialogue on the unsuitability of PDFs for providing context to AI and the importance of using structured formats like JSON or XML.
- Discussions on perceived declines in ChatGPT’s performance, prompting speculation on possible reasons ranging from deliberate degradation to poor prompt design.
- Exploration of task-specific summarization using the OpenAI API and a member looking to combine AI with blockchain technology.
- Enthusiasm over Meta's Llama 3 model and the speculation surrounding its potential and impact on the AI landscape.
- Concerns and predictions about the real-world usability and scale of the 405 billion parameter Llama 3 model.
Discussion on New Language Models and Tools
Clarification on Docker Usage:
It was discussed whether it is possible to work without Docker, along with potential outdated information in official documentation. A <a href='https://github.com/cohere-ai/quick-start-connectors/tree/main/mysql?utm_source=ainews&utm_medium=email&utm_campaign=ainews-llama-3' target='_blank'>GitHub repository</a> was provided for reference.
-
Commercial Use of Command R/R+ on Edge Devices: The limitations on commercial use of Command R and Command R+ due to CC-BY-NC 4.0 licensing restrictions were clarified.
-
Model Deployment Conversations: Community members discussed the deployment of large models, mentioning hardware like dual A100 40GBs and MacBook M1.
-
Project Discussions: There were discussions on various projects like jailbreaks evolving in Large Language Models, model integration with monitoring tools, and building RAG applications with open tools.
LangChain AI Forum Discussions
The LangChain AI section discusses various topics such as using Runnable Class in LangChain, learning RAG with LangChain, handling dates with LLM, integration inquiries with Vertex AI and Claude 3, and understanding LLAMA 3 functionality. The discussions include sharing helpful resources, code usage, and implementation details related to LangChain and its associated projects.
Skunkworks AI ▷ #finetuning
Databricks Enhances Model Serving:
- Databricks introduced GPU and LLM optimization support for Model Serving, simplifying AI model deployment and optimizing LLM serving with zero configuration.
The Cost of Innovation Might Pinch:
- A member humorously mentioned that Databricks' GPU and LLM optimization support for Model Serving could be expensive.
Fine-Tuning LLMs Made Easier:
- Modal shared a guide to fine-tuning LLMs, featuring advanced techniques like LoRA adapters, Flash Attention, gradient checkpointing, and DeepSpeed for efficient model weight adjustments.
Serverless Hosting for Wallet-Conscious Developers:
- An example on GitHub offers affordable serverless GPU hosting solutions.
Member Finds Serverless Inference Solution:
- A member expressed satisfaction with discovering serverless inference options aligning with their requirements.
FAQ
Q: What is Meta's Llama 3 and what are its key capabilities?
A: Meta's Llama 3 is a series of large language models with different parameters, including 8B and 70B models. The 70B model outperforms previous versions like Llama 2, providing GPT-4 level performance at a lower cost. Llama 3 excels in tasks like function calling and arithmetic.
Q: What are some discussions around AI scaling challenges and compute requirements?
A: Discussions highlight the rapid increase in AI's energy usage and GPU demand, with concerns about potentially overwhelming energy sources by 2030. There's also talk about the immense GPUs required for training future models.
Q: What are some debates and discussions around AI safety, bias, and societal impact?
A: Debates focus on political bias in AI models, discussions on AI's potential to break encryption, and considerations between AI doomerism and optimism for beneficial AI development.
Q: What are some noteworthy updates and discussions related to Llama 3 across different AI communities?
A: Discussions cover various aspects like the performance and integration of Llama 3, comparative benchmarks with other models, hardware compatibility, innovative training strategies, and advancements in the AI landscape. Specific highlights include advancements in language modeling, challenges with AI model training on specific hardware configurations, and efforts towards optimizing AI model performance.
Q: What are some technical challenges faced by users related to Llama 3?
A: Users have faced challenges like merging qlora adapter into Llama 3, errors with tokenizer loading, unexpected keyword arguments during finetuning, and seeking support for AMD GPUs.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!