[AINews] Meta Llama 3 (8B, 70B) • ButtondownTwitterTwitter
Chapters
AI Discord Recap
LlamaIndex
Interconnects and AI Breakthroughs
AI Community Discussions on Discord
Interesting Links Discussed in Nous Research AI Channel
LM Studio Chat - Models Discussion
LM Studio: Unsloth AI (Daniel Han)
Meta Llama 3: Release Details and New Model Versions
CUDA Programming and AI Development Discussions
Llama, Axolotl, and Model Discussions
Eleuther Discord Channels
Mojo and Modular Updates
Discussion on Scaling Laws and Model Analysis
Chat Platform Discussions
LangChain AI Updates
Datasette - LLM (@SimonW)
AI Discord Recap
AI Discord Recap
A summary of summaries of summaries has been provided in the AI Discord recap section. The section highlights the excitement generated by the launch of Meta's Llama 3 models, the efficiency and performance of Mixtral 8x22B, scrutiny on tokenizers and multilingual capabilities, debates on scaling laws and replication challenges in AI research, and various miscellaneous topics. The recap covers a wide range of discussions and developments in the AI Discord community, showcasing the latest trends and advancements in the field.
LlamaIndex
LlamaIndex
-
Stable Diffusion 3 by Stability AI has been launched on API with mixed reception. The model brings advancements in typography and prompt adherence, but faces criticism for performance issues and a steep price increase. Absence for local use has also drawn backlash, with promises from Stability AI to offer weights to members soon.
-
CUDA engineers tackled challenges like tiled matrix multiplication and custom kernel compatibility with torch.compile. Discussions covered memory access patterns, warp allocation, and techniques like Half-Quadratic Quantization (HQQ). Projects like llm.c saw optimizations reducing memory usage and speeding up attention mechanisms.
-
The AI ecosystem witnessed new platforms and funding, with theaiplugs.com debuting as a marketplace for AI plugins, SpeedLegal launching on Product Hunt, and a dataset compiling $30 billion in AI startup funding across 550 rounds. Platforms like Cohere and Replicate introduced new models and pricing structures, indicating a maturing ecosystem.
Interconnects and AI Breakthroughs
The Interconnects Discord section discusses a fusion of Monte Carlo Tree Search (MCTS) with Proximal Policy Optimization (PPO) leading to a new PPO-MCTS value-guided decoding algorithm. Additionally, the section highlights new advanced language models such as Mixtral 8x22B and OLMo 1.7 7B, along with debates around the Chinchilla paper's disputed scaling laws. The release of Meta's LLaMa 3 and its features were explored in a YouTube video. The section also covers AI community discussions on real-world applicability, model showdowns, AI fundraising insights, and challenges faced in model training and optimization.
AI Community Discussions on Discord
The AI community is abuzz with various discussions on Skunkworks AI, Mozilla AI, LLM Perf Enthusiasts AI, and AI21 Labs (Jamba) Discord channels. Topics include new AI model launches, serverless fine-tuning, avoiding exposure of LLM APIs, and inquiries about tool usage and distributed inference implementation. Each channel provides a platform for members to share insights, ask questions, and explore the latest advancements in the AI field.
Interesting Links Discussed in Nous Research AI Channel
Check out the interesting links discussed in the Nous Research AI channel:
- Tokenization Decoded by Mistral AI: Mistral AI has open-sourced their tokenizer, breaking down text into smaller subword units for language models.
- Skeptical About Tokenization Overhype: Discussion on the significance of tokenization in models like Opus.
- Hugging Face Security Breach Revealed: A YouTube video discusses a security incident involving Hugging Face due to a malicious file.
- Potential Exploits with Pickles in OpenAI: Risks associated with using insecure pickles in OpenAI's environment.
- State of AI in 2023 via Stanford’s AI Index: The latest Stanford AI Index report is released, summarizing trends and advancements in the AI field.
LM Studio Chat - Models Discussion
New Meta Llama 3 Model Drops:
Users are experimenting with prompt presets to address issues with unexpected output repetition and prompt loops.
Llama 3 Preset Confusion:
Members seek advice on the right configuration for Llama 3 prompt templates, reporting some success with latest presets.
Llama CPP Issues & Fixes:
Discussions focus on llama.cpp nuances and resolving problems around model generation behavior.
Performance and Hardware Talk:
Excitement surrounds Llama 3 performance on different specs, with specific interest in running larger models efficiently.
Quantization and Quality:
Debates on perceptible quality differences between quant levels, including discussions around 2-bit IQ quants with minimal quality degradation.
LM Studio: Unsloth AI (Daniel Han)
Discussion Highlights
- Users discussing the performance of Llama 3 model in terms of benchmark results and features compared to Llama 2.
- Active integration efforts of Llama 3 in Unsloth AI, including a Google Colab notebook for the 8B model and plans for a 4bit quantized version.
- Reports on issues with the Llama 3-instruct model generating endless outputs due to End-of-Sequence token problems, with suggested workarounds for modifying gguf files.
- User inquiries about support for older GPU generations by Unsloth and discussions on alternative personal knowledge management tools like Obsidian for note-taking.
- Importance of adhering to new licensing terms for Llama 3 derivatives, requiring them to be prefixed with "Llama 3" and updating licensing details accordingly.
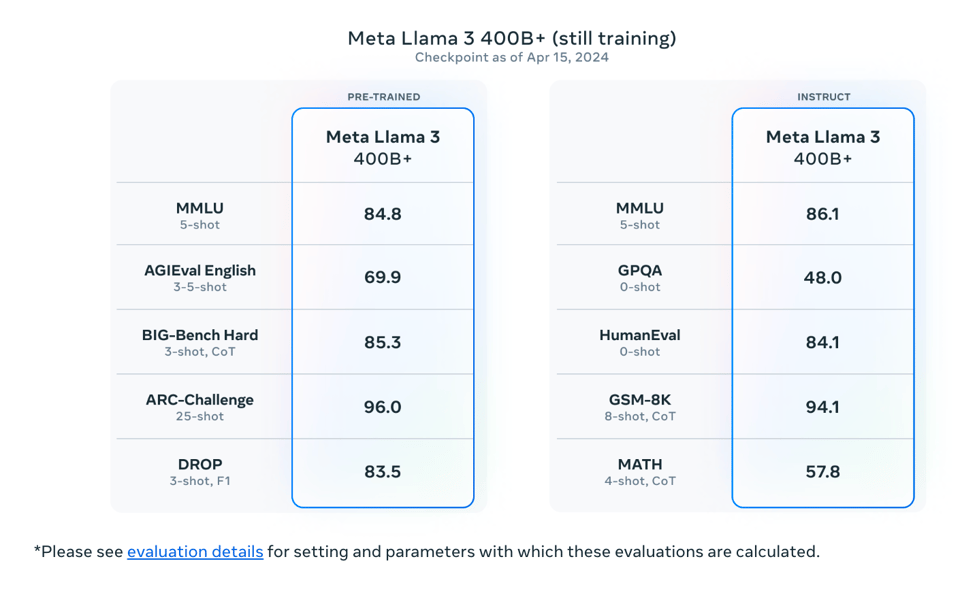
Meta Llama 3: Release Details and New Model Versions
Today, 18 April 2024, marked the release of @meta's LLaMA 3, introducing its third iteration. This new model boasts finetuning capabilities at double the speed and with 60% less memory usage than previous versions. A Google Colab notebook has been provided for users to try out the Llama-3 8b. Additionally, more efficient 4-bit versions of Llama-3 are now available on Hugging Face, under the names Llama-3 8b, 4bit bnb, and Llama-3 70b, 4bit bnb. Users are encouraged to test the Llama-3 model and share their results with the community. It is recommended to update to the latest Unsloth package version for those not utilizing the new Colab notebooks.
CUDA Programming and AI Development Discussions
This section includes various discussions related to CUDA programming and AI development. It covers topics such as programming heterogeneous computing systems with GPUs and other accelerators, reevaluation and future plans for projects like RingAttention, Triton language math operations, quantization strategies, new techniques for quantization, enhancements in quantization methods and HQQ adaptation, issues with model concatenation affecting quantization, efficiency improvements on attention mechanisms, and technical discussions on fused classifier kernels. Additionally, there are discussions on event recording coordination, model performance comparisons, cost-efficiency in training GANs, Microsoft's VASA-1 project, HQ-Edit image editing dataset, and Meta's introduction of Llama 3 large language model.
Llama, Axolotl, and Model Discussions
Llama 3 Launching Details and Speculations:
Meta launched Llama 3 with 8B and 70B models featuring a Tiktoken-based tokenizer, 8k context length, and benchmarks showing competitive performance. Discussions speculate on its immediate capabilities and improvements.
Axolotl PR Submitted for Llama 3 Qlora:
A Pull Request was opened to add Llama 3 Qlora to Axolotl, with discussions surrounding technical implementation and potential issues.
Merging Model Adapter After Finetuning Issues:
A user resolved issues merging their Qlora adapter into the base Llama 3 model post-finetuning.
Training and Context Size Technical Discussions:
Conversations took place regarding extending context sizes beyond default settings, with users sharing insights and experiences.
Community Sentiments on Llama 3's Impact on Existing Work:
Reactions varied with the release of Llama 3, with some users expressing excitement over benchmarks while others were skeptical about the 70B model's performance leap over the 8B model.
Eleuther Discord Channels
The Eleuther Discord channels cover a wide range of topics in the field of machine learning and AI. Discussions include revisiting scaling laws, multilingual models, untied embeddings, handling variable-length inputs, improving reasoning with MCTS, and more. There are debates on statistics, estimating training flops, scaling policies, and the impact of data scaling. Clarifications on accuracy metrics and connections between benchmarks like MMLU and ARC are also explored.
Mojo and Modular Updates
Loglikelihood Computation Specifics
- Focus on continuation/target when computing loglikelihood to calculate perplexity specifically over the generated continuation.
Significant Speed Boost Using vLLM
- Users reported a 10x speed-up with vLLM compared to a regular text-generate pipeline due to an improved setup.
Support Request for PR Reviews
- Contributions for flores-200 and sib-200 benchmarks were shared, emphasizing the need for streamlined methods to review and merge config-rich tasks effectively.
Mojo Updates
- Plugin released for Mojo on PyCharm with plans for enhanced support.
- Discussions on using Mojo for Windows users, adding features to Mojo Playground, integrating C with Mojo, and managing stringable tuples and list operations.
Nathan Lambert's Interconnects Updates
- Exploration of Monte Carlo Tree Search (MCTS) combined with Proximal Policy Optimization (PPO) and introduction of the PPO-MCTS algorithm.
- News on Mixtral 8x22B, OLMo 1.7 7B, Meta Llama 3 models, and Replicate's cost-efficient model infrastructure.
Nightly Updates
- Updates on proper functioning of traits, clean-up efforts, Mojo format conventions, naming challenges, and installation hiccups resolved.
ML-Questions Updates
- Controversy sparked by a tweet questioning findings on Chinchilla scaling.
Discussion on Scaling Laws and Model Analysis
In this section, various viewpoints and discussions regarding the scaling paper by Hoffmann et al. are highlighted. The skepticism around extrapolations made from fitting data to a single line, frustration over authors' silence, and analysis of the Chinchilla paper by different individuals are detailed. Additionally, an admission of error in the Chinchilla paper and the decision to open source data for transparency are discussed. The tweets referenced and the links mentioned provide further insights into the ongoing debate and critiques surrounding scaling laws in influential research work.
Chat Platform Discussions
- The section discusses various topics related to different channels on a chat platform.
- Members initiated the 'llm-paper-club-west' meeting, transitioned to Zoom, and ensured smooth coordination for the session.
- Users encountered challenges with OpenInterpreter setup on Windows but expressed optimism about its potential.
- Members inquired about using local language models in OpenInterpreter tasks and discussed experimenting with powerful hardware for enhanced performance.
- Users on another channel discussed setting up O1, Windows errors, and ESP32 device challenges.
- Assistance was sought for websockets issues and using different language models with OpenInterpreter.
- The section also includes discussions on the state-of-the-art MistralAI model supported by LlamaIndex and tutorials on building RAG applications with Elasticsearch and LlamaIndex.
LangChain AI Updates
The LangChain AI section includes a request for a tutorial on adding feedback through langserve using JavaScript, the launch of the AI Plugin Marketplace on theaiplugs.com, a call for support for a startup on Product Hunt called SpeedLegal, the availability of a new prompt engineering course on LinkedIn Learning, and the public use of Llama 3 accessible for chat and API. Various links mentioned include the AI marketplace, Tune Chat for content writing, Llama 3 for public use, and a course on prompt engineering. The section highlights ongoing discussions and announcements within the LangChain AI community.
Datasette - LLM (@SimonW)
-
A member announced the launch of their startup on Product Hunt and sought support and feedback from the community.
-
Andrej Karpathy suggests that a smaller model (8B parameters) trained on a large dataset (15T tokens) could be just as effective as larger counterparts. The concept of long-trained, smaller models is positively received by the community.
-
A bug was reported in llm-gpt4all regarding new installs causing python apps to break. Issues with plugin development and management were also discussed, with a member ultimately opting to reinstall llm to resolve plugin problems.
FAQ
Q: What is the significance of the launch of Meta's Llama 3 models?
A: The launch of Meta's Llama 3 models signifies advancements in finetuning capabilities, improved speed, and reduced memory usage compared to previous versions.
Q: What are some key discussions surrounding the Llama 3 model?
A: Discussions include topics like prompt presets for avoiding unexpected output repetition, debates on llama.cpp nuances, issues with model generation behavior, and debates on quantization levels and quality.
Q: What are some areas of focus in discussions related to CUDA programming and AI development?
A: Discussions cover topics such as heterogeneous computing systems with GPUs, memory optimizations like Half-Quadratic Quantization, new platforms and funding in the AI ecosystem, and advancements in attention mechanisms.
Q: What are some updates and speculations regarding the launch of Llama 3 models?
A: Updates include the introduction of Tiktoken-based tokenizer, discussion on model adapters and training issues, community sentiments on impact, and speculations on immediate capabilities and improvements of the new Llama 3 models.
Q: What are some discussions and debates surrounding scaling laws in AI research?
A: Discussions include skepticism around extrapolations made in research papers like the Chinchilla scaling laws, frustration over lack of transparency, analysis of data fitting, and debates on the impact of data scaling and statistics.
Q: What interesting links and topics were discussed in the Nous Research AI channel?
A: Topics covered include open-sourced tokenizer by Mistral AI, security breach at Hugging Face, risks with using pickles in OpenAI, and the release of the latest Stanford AI Index report summarizing trends in the AI field.
Q: What are some community sentiments and user experiences with the Llama 3 model?
A: Feedback includes excitement over benchmark results and efficient performance of Llama 3, concerns over model generation issues, inquiries about GPU support, and discussions on licensing terms for derivative works.
Q: What are the key updates and discussions mentioned in the Eleuther Discord channels?
A: Updates include exploring MCTS with PPO, advancements in language models like Mixtral 8x22B and OLMo 1.7 7B, discussions on scaling laws and multilingual models, and debates on statistics and training flops.
Q: What are some specific sections highlighted in the Interconnects Discord updates?
A: Content includes discussions on Mojo updates, Nathan Lambert's updates on PPO-MCTS algorithm, nightly updates, and the controversy sparked by a tweet questioning findings on Chinchilla scaling.
Q: What are some of the topics discussed in the LangChain AI section?
A: Topics include AI Plugin Marketplace launch, calls for support for startups like SpeedLegal, availability of prompt engineering courses, discussions on smaller effective models, and public use of Llama 3 for chat and API.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!