[AINews] Mistral Large 2 + RIP Mistral 7B, 8x7B, 8x22B • ButtondownTwitterTwitter
Chapters
AI Reddit and Twitter Recaps
High-Level Discord Summaries: Mistral Large 2 Model Features
Nous Research AI Discord
Feature Enhancements and New Programs
Insights on Training and Network Topology
LM Studio Hardware Discussion
Perplexity AI Announcements
Workflow Techniques and Document Generation
Utilizing SMT Solvers, Repo Updates, Moral Dilemmas, and Structured Reasoning
Eleuther LM Thunderdome
Cool Links
Insights on Mistral Large Model and FlashAttention Updates
LlamaIndex: General Conversations and Challenges
Discussions on AI Projects and Tools
OpenInterpreter and LLM Finetuning Discussions
AI News on Social Networks and Newsletter
AI Reddit and Twitter Recaps
The AI Reddit Recap includes highlights from /r/LocalLlama, discussing themes like the release of Llama 3.1 models by Meta and details revealed in the Llama 3.1 paper. Meanwhile, the AI Twitter Recap mentions that all recaps were done by Claude 3.5 Sonnet with the best of 4 runs, and there was a temporary outage. These recaps provide insights and updates on AI-related discussions happening on social media platforms.
High-Level Discord Summaries: Mistral Large 2 Model Features
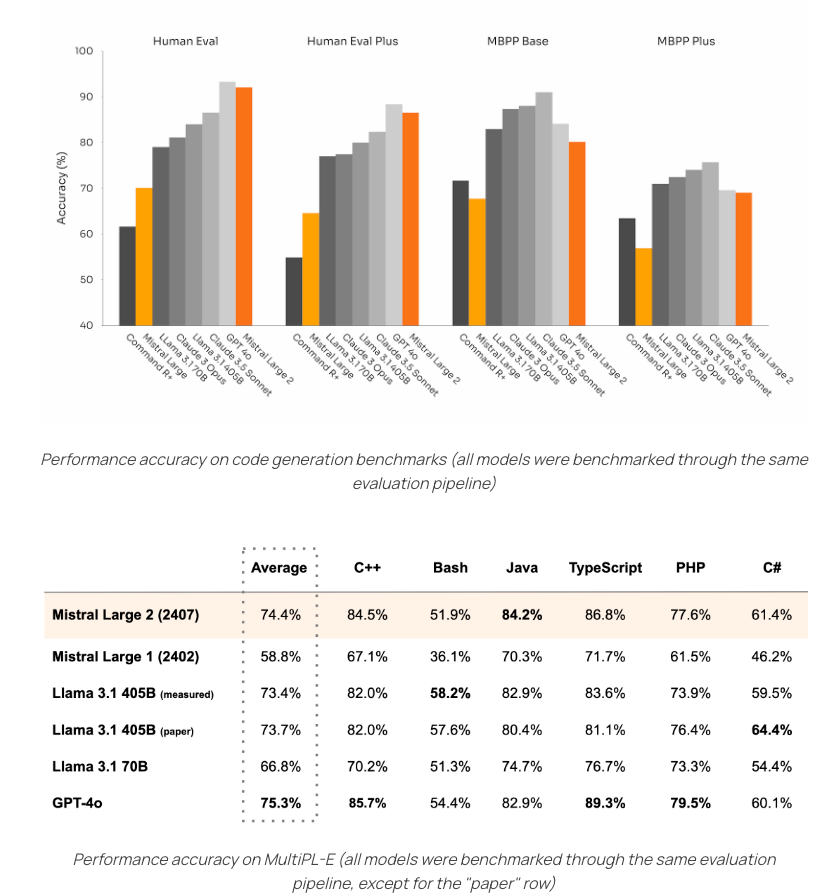
On July 24, 2024, Mistral AI launched Mistral Large 2, featuring an impressive 123 billion parameters and a 128,000-token context window, pushing AI capabilities further. This model outperforms Llama 3.1 405B, particularly in complex mathematical tasks, making it a strong competitor in the AI landscape. Mistral Large 2 boasts multilingual support and longer context windows compared to existing models, showcasing ongoing performance enhancement efforts in this evolving market.
Nous Research AI Discord
Members on the Nous Research AI Discord channel discussed advancements in LLM distillation techniques, the introduction of LLaMa 3 with 405B parameters, Mistral Large 2's competitive edge, challenges with fine-tuning Llama 3 405B, and debates on moral reasoning tasks. The community engaged in collaborative discussions on various AI applications and enhancements in document generation processes.
Feature Enhancements and New Programs
Summary of Feature Enhancements and New Programs: LlamaParse now supports Markdown output, JSON mode, and plain text. MongoDB introduced MAAP for simplifying AI-enhanced applications. Mistral Large 2 rolled out function calling capabilities and structured outputs. Discussions on SubQuestionQueryEngine for streaming responses. Skepticism over Llama 3.1 metrics. Issues reported with Cohere dashboard reloading. Appreciation for Command R Plus capabilities. Concerns over server performance. Suggestions for innovative features in Cohere. New members introduce themselves with NLP and NeuroAI backgrounds.
Insights on Training and Network Topology
The Llama3.1 paper by Meta showcases valuable insights for the open source community, including details on training a model with 405 billion parameters and network topology used for their 24k H100 cluster. The paper also discusses training interruptions, server issues, and the need for better benchmarks in hallucination prevention techniques.
LM Studio Hardware Discussion
This section discusses various hardware-related topics among LM Studio users. The topics include the transition of OpenCL to Vulkan in LM Studio, comparisons between RTX 4090 and RX 7900 XTX GPUs for streaming, fine-tuning VRAM requirements for the LLaMA 3.1 8B model, recommendations for budget-friendly GPUs like the RTX 3060 12GB, and exploring tech opportunities in Taiwan. Users shared insights on GPU performance, compatibility issues, and experiences with different hardware setups.
Perplexity AI Announcements
The Perplexity AI channel discussed the launch of Llama 3.1 405B model, stating it rivals GPT-4o and Claude Sonnet 3.5. They are working on integrating Llama 3.1 405B into their mobile apps and have plans for upcoming mobile app integration. Members expressed skepticism about Llama 405b's performance, praising Mistral Large 2 as a potentially better model. There were discussions on AI model benchmarks, TikTok as a search tool, and language symbol output issues. Users were encouraged to stay tuned for more updates.
Workflow Techniques and Document Generation
Initiated discussions on leveraging OpenAI for document generation techniques. Members identified and planned for debugging model outputs, focusing on spelling mistakes like 'itis' instead of 'it is.' Specific examples were shared to understand model tendencies better. Users shared experiences of deliberately provoking misspellings in conversations and provided feedback, showcasing their link interactions. Additionally, recent advancements in LLM distillation were highlighted, introducing new models like LLaMa 3 with enhanced parameters and capabilities. Common challenges in production environments related to Retrieval-Augmented Generation (RAG) were also discussed, aiming to provide potential solutions for practitioners. Further engagement included an exciting PC Agent Demo release, discussions on proprietary tools, and interesting links shared among the community.
Utilizing SMT Solvers, Repo Updates, Moral Dilemmas, and Structured Reasoning
- Utilizing SMT Solvers for LLMs: Teaching LLMs to translate word problems using SMTLIB can enhance reasoning capabilities and model performance.
- Repo Structure Updates In Progress: Plans to update the repository's structure and schemas were announced, inviting collaboration from the community.
- Moral Dilemmas in Reasoning Tasks: Discussions on including difficult moral queries like the trolley problem challenge models' moral principles.
- Reflection on the Trolley Problem: Concerns raised about assessing moral foundations through the trolley problem and suggestions for clarifying prompts.
- Structured Reasoning in Moral Queries: Sharing a structured framework to analyze moral implications of decisions to improve moral reasoning.
Eleuther LM Thunderdome
Members of Eleuther LM Thunderdome discussed the evaluation of Llama API using lm_eval, addressing errors related to logits and multiple-choice tasks. They shared troubleshooting attempts and solutions for issues encountered. The conversation also touched on the handling of multiple-choice questions, specifically errors experienced with tasks like mmlu_college_biology. Members sought compatibility between API outputs and the evaluation framework, sharing error logs for further analysis.
Cool Links
VLMs outperforming in text generation:
A discussion highlighted that even when VLMs are available, they typically excel in text tasks over image processing, as shown with GPT-4o's performance on the ARC test set.
- Ryan found that feature engineering the problem grid yielded better results compared to relying entirely on GPT-4o's vision capabilities.
CUDA aiming to surpass cuBLAS:
A member announced upcoming CUDA advancements, stating, 'we are going to outperform cuBLAS on a wide range of matrix sizes'.
- This includes potential enhancements not only for SGEMM but for other operation types as well.
Mistral Large 2 showcases advanced features:
Mistral Large 2 boasts a 128k context window with support for multiple languages and 80+ coding languages, designed for efficient single-node inference.
- With 123 billion parameters, it is geared towards long-context applications and is released under a research license allowing for non-commercial usage.
Impact of FP16/FP32 on performance:
Discussion surfaced around NVIDIA's hardware intrinsics for FP16/FP32, which could significantly influence performance outcomes.
- This has generated excitement for future developments in the CUDA ecosystem.
Interesting Benchmark Comparisons:
Members found Mistral's latest benchmarks intriguing as they 'push the boundaries of cost efficiency, speed, and performance'.
- The new features provided facilitate building innovative AI applications for various contexts.
Insights on Mistral Large Model and FlashAttention Updates
The section discusses updates related to Mistral Large Model and FlashAttention. For Mistral, Mistral-Large-Instruct-2407 with 123B parameters and multilingual capabilities was released. There were also discussions on model performance, training challenges, and synthetic data generation. On the other hand, FlashAttention now supports AMD ROCm in the FlashAttention 2 library through a recent GitHub Pull Request #1010. The section highlights limited compatibility with MI200 & MI300 and ongoing discussions on adapter fine-tuning, Llama-3.1 errors, and more.
LlamaIndex: General Conversations and Challenges
In the LlamaIndex general channel, members discussed various topics including streaming responses with SubQuestionQueryEngine to reduce latency, skepticism about Llama 3.1 metrics usability for RAG evaluations, optimizing RAG setups with PDF interfaces for web display, improving Text-to-SQL pipeline speed, and addressing issues with ReAct agents hallucinating due to incorrect processing loops. The community shared solutions, recommendations, and sought advice on enhancing their workflows and model performances.
Discussions on AI Projects and Tools
- LlamaIndex Discussions: Members seek advice on improving the OpenAIAgent tool usage and share insights on developing custom evaluation systems for the RAG pipeline. They also discuss suggestions for enhancing RAG evaluation methods.
- Cohere Community Interactions: Cohere users discuss reloading issues, appreciate new models like Llama 3.1, inquire about server performance, suggest new features for Cohere tools, and introduce themselves in the community.
- DSPy Community Conversations: Members face challenges with typed predictors, seek ways to inspect internal program execution, advocate for small language models, discuss contributing to DSPy examples, and inquire about model fine-tuning with DSPy.
- tinygrad and George Hotz discussions: Community members exchange insights on learning Tinygrad, resolving GPU and Uops issues, checking closed PRs, understanding OpenCL and Python limitations, implementing a Molecular Dynamics engine, creating custom runtimes, optimizing neural network potentials, and implementing the PPO algorithm.
- Torchtune Community Exchange: Torchtune discussions highlight interviews for the 3.1 release, a pull request for MPS support, challenges with LoRA functionality, dealing with Git conflicts, and optimizing Git workflows.
- LangChain AI Forum: Discussions include exploring Hugging Face agents, seeking job opportunities in Python, solving HNSW and IVFFLAT index challenges, and managing SQLite server storage. Users also address challenges in scaling LangServe to handle high concurrent requests effectively.
OpenInterpreter and LLM Finetuning Discussions
The section discusses various topics related to OpenInterpreter and LLM finetuning. It covers the introduction of an AI Code Reviewer tool, API usage with Nvidia credits, comparisons between Mistral Large 2 and Llama 3.1 405 B, developer opportunities, and excitement for integrating with LM Studio. Additionally, there are conversations about translation model fine-tuning with DPO, CPO's role in improving translation models, ALMA-R's standout performance, and legal considerations in ML datasets. The threads delve into legal issues, dataset complexities, community anticipation for device shipping, and insights from the Llama3.1 paper, including training insights and network topology descriptions.
AI News on Social Networks and Newsletter
This section provides links to find AI News on social media and a newsletter. You can follow Latent Space on Twitter at Latent Space Twitter and subscribe to their newsletter at Latent Space Newsletter. The content is brought to you by Buttondown, a platform that facilitates starting and growing newsletters.
FAQ
Q: What are some key highlights discussed in the AI Reddit Recap?
A: The AI Reddit Recap includes discussions on the release of Llama 3.1 models by Meta and details revealed in the Llama 3.1 paper.
Q: What are the main updates shared about Mistral Large 2 on July 24, 2024?
A: Mistral AI launched Mistral Large 2 with 123 billion parameters and a 128,000-token context window, pushing AI capabilities further and outperforming Llama 3.1 405B in complex mathematical tasks.
Q: What were some key discussions on the Nous Research AI Discord channel?
A: Discussions included advancements in LLM distillation techniques, the introduction of LLaMa 3 with 405B parameters, Mistral Large 2's competitive edge, challenges with fine-tuning Llama 3 405B, and debates on moral reasoning tasks.
Q: What feature enhancements and new programs were summarized in the text?
A: LlamaParse now supports Markdown output, JSON mode, and plain text. MongoDB introduced MAAP, Mistral Large 2 rolled out function calling capabilities, and structured outputs. Discussions on SubQuestionQueryEngine, Cohere dashboard reloading issues, Command R Plus capabilities, and more were highlighted.
Q: What valuable insights were showcased in the Llama 3.1 paper by Meta?
A: The paper discussed training a model with 405 billion parameters, network topology used for their 24k H100 cluster, training interruptions, server issues, and the need for better benchmarks in hallucination prevention techniques.
Q: What were some hardware-related topics discussed among LM Studio users?
A: Topics included the transition of OpenCL to Vulkan, comparisons between RTX 4090 and RX 7900 XTX GPUs, fine-tuning VRAM requirements for LLaMA 3.1 8B model, recommendations for budget-friendly GPUs like RTX 3060 12GB, and exploring tech opportunities in Taiwan.
Q: What were the highlights in the discussion around Mistral Large 2 and FlashAttention?
A: Mistral Large 2 released with 123B parameters and FlashAttention now supports AMD ROCm. Discussions covered model performance, training challenges, synthetic data generation, limited compatibility with MI200 & MI300, adapter fine-tuning, Llama-3.1 errors, and more.
Q: What were some topics discussed in the LlamaIndex general channel?
A: Topics included streaming responses with SubQuestionQueryEngine, skepticism about Llama 3.1 metrics, RAG evaluations, optimizing RAG setups, improving Text-to-SQL pipeline speed, and addressing issues with ReAct agents hallucinating.
Q: What were some insights shared in the discussions related to OpenInterpreter and LLM finetuning?
A: Discussions covered an AI Code Reviewer tool introduction, API usage with Nvidia credits, Mistral Large 2 vs. Llama 3.1 405 B comparisons, developer opportunities, translation model fine-tuning with DPO, CPO's role in improving translation models, legal considerations in ML datasets, and more.
Q: Where can one find AI News on social media and subscribe to a newsletter mentioned in the text?
A: You can follow Latent Space on Twitter at 'Latent Space Twitter' and subscribe to their newsletter at 'Latent Space Newsletter'. The content is brought to you by Buttondown, a platform that facilitates starting and growing newsletters.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!