[AINews] Qdrant's BM42: "Please don't trust us" • ButtondownTwitterTwitter
Chapters
AI Twitter Recap
AI Reddit Recap
LAION Discord
Interconnects and Discoveries
OpenAccess AI Collective (axolotl) Discord
HuggingFace NLP
Unsloth AI (Daniel Han) General Discussions
Latent Space ▷ #ai-announcements
Discussions on LM Studio Hardware Compatibility and Functionality
Perplexity AI General Discussion
OpenAI Discussions
OpenRouter (Alex Atallah) App Showcase and General Messages
Debugging and Security in Open Interpreter Community
Diverse Topics on Mojo, AI Olympiads, and LLM Finetuning
OpenAccess AI Collective (axolotl) General
MLOps @Chipro ▷ #events
AI Twitter Recap
This section provides a recap of AI-related discussions on Twitter. The recap includes mentions of issues with Stripe accounts, specifically problems with holding money, as highlighted by @HamelHusain, and alternatives mentioned by @jeremyphoward. Additionally, the section notes that all recaps are done by Claude 3.5 Sonnet.
AI Reddit Recap
AI Progress and Implications
- An article questions the economic impact of AI despite the hype.
- Studies show AI-generated humor rated funnier than humans.
- A hacker breached OpenAI's communication systems, raising IP theft concerns.
- Major anti-aging effects seen in mice, with human trials next.
AI Models and Capabilities
- New models like Gemma 2 and nanoLLaVA-1.5 improve speed and performance.
- Reflection as a Service introduced for LLMs to validate outputs.
AI Safety and Security
- Discussion on securing LLM apps and limitations of current AI trustworthiness.
AI Art and Media
- Workflows shared for generating AI singers and transferring facial expressions.
- Prediction of demand for live entertainment with AI advancements.
Robotics and Embodied AI
- Videos shared of Menteebot and Japan's giant humanoid robot development.
- Call for the development of open source mechs.
Miscellaneous
- Concern over the sudden disappearance of Auto-Photoshop-StableDiffusion plugin developer.
- Extreme horror-themed 16.5B LLaMA model shared.
- Discussion on the 'Singularity Paradox' thought experiment.
LAION Discord
The LAION Discord channel discusses various topics such as the new features of BUD-E, issues with Clipdrop's NSFW detection, the introduction of the T-FREE tokenizer, a scammer encountered in the guild, and experiences with scammers. The community explores AI model training challenges, license revisions by Stability AI, and recent tool developments like the T-FREE tokenizer. Moreover, discussions include the implications of GPT's memory capabilities, contests for traffic tickets, and strategies for employee recognition programs.
Interconnects and Discoveries
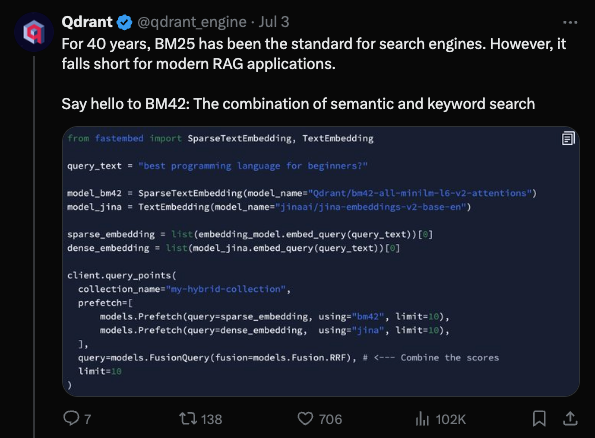
The discussions in this section explore various topics such as debunking AI demos, comparing search technologies BM42 and BM25, and challenging the legitimacy of AI models. Members also seek clarity on training tweaks, monthly credit terms, and course catch-up. Notable interactions include revisions made by Stability AI and debates surrounding the Qdrant Engine's BM42 technology.
OpenAccess AI Collective (axolotl) Discord
API Queue System Quirks: Reports of issues with the build.nvidia API led to discovery of a new queue system to manage requests, signaling a potentially overloaded service.
- A member encountered script issues with build.nvidia API, observing restored functionality after temporary downtime hinting at service intermittency.
YAML Yields Pipeline Progress: A member shared their pipeline's integration of YAML examples for few-shot learning conversation models, sparking interest for its application with textbook data.
- Further clarifications were provided on how the YAML-based structure contributed to efficient few-shot learning processes within the pipeline.
Gemma2 Garners Stability: Gemma2 update brought solutions to past bugs. A reinforcement of version control with a pinned version of transformers ensures smoother future updates.
- Continuous Integration (CI) tools were lauded for their role in preemptively catching issues, promoting a robust environment against development woes.
A Call for More VRAM: A succinct but telling message from 'le_mess' underlined the perennial need within the group: a request for more VRAM.
- The single-line plea reflects the ongoing demand for higher performance computing resources among practitioners, without further elaboration in the conversation.
HuggingFace NLP
Meta-LLaMA download struggles: A user expressed frustration over Meta-LLaMA taking forever to download and worries about potential space issues. API call confusion: There was confusion on building an API call to a model without local download. Mistral model freezes: Mistral froze during inference, suspected of a caching issue. Static KV cache confusion: Users noted the default static KV cache since version 4.41. TypedStorage deprecation concerns: Concerns raised on TypedStorage deprecation.
Unsloth AI (Daniel Han) General Discussions
Gemma 2 Release brings speed and VRAM improvements: The Gemma 2 Release offers faster finetuning and a reduction in VRAM usage compared to Flash Attention 2. Users noted some rushed aspects in a community member's blog post. Unsloth notebooks and model directory issues: Users reported problems with Gemma 2 notebooks, including naming errors. Collaborative efforts were made to address these issues. Training on long-context examples and dataset preparation techniques: Members discussed handling long-context datasets, sharing advice on setting appropriate context lengths and utilizing specific functions to find max tokens. Gemma 2 performance and limitations without Flash Attention support: In the absence of Flash Attention support, Gemma 2 models are reported to be slow and nearly unusable for intense tasks. Suggestions were made regarding more efficient approaches like gradacc. New AI models and tools announcements: Nomic AI introduced GPT4ALL 3.0, while InternLM-XComposer-2.5 was highlighted for its support of long-context input and output.
Latent Space ▷ #ai-announcements
- Yi Tay on YOLO Researcher Metagame: New podcast episode with Yi Tay of Reka discussing his team's journey in building a new training stack from scratch and training frontier models purely based on gut feeling. Comparisons to OpenAI and Google Gemini team sizes were made, reflecting on the research culture at Reka. Detailed topics include LLM trends, RAG, and Open Source vs Closed Models.
- Now on Hacker News: Latent Space Podcast episode with Yi Tay is now featured on Hacker News. Engage with the discussion and vote for visibility.
Discussions on LM Studio Hardware Compatibility and Functionality
The section discusses various hardware-related topics related to LM Studio. It covers the compatibility of different GPUs with models, struggles faced with certain model sizes, and suggested models for mid-range GPU setups. It also delves into the details of Snapdragon Elite performance on Surface Laptops, with discussions on NPU support and delays in implementation. Additionally, members share their positive experiences with the Surface Laptop and its capabilities. The section also features discussions on AppImage compatibility, ARM CPU support, and successful ROCm installation scripts. Finally, it touches upon discussions in various channels related to CUDA, Torch, algorithms, and beginner topics.
Perplexity AI General Discussion
Users on Perplexity AI reported issues with repetitive answers and live internet access problems. Users also expressed frustration with inaccuracies in Perplexity Pro's math calculations and shared positive experiences in using Perplexity AI for stock market analysis. Discussions also revolved around subscription plans and model usage differences.
OpenAI Discussions
The discussions in the OpenAI channels cover a range of topics related to AI technology and developments. Some of the highlights include the benefits of a paid ChatGPT plan, the handling of images and PDFs in GPT knowledge base, discussions on GPT memory effectiveness, linking GPT knowledge bases to external document services, and cooldown periods for using GPT-4. The channels also delve into prompt engineering for training courses, testing multiple AI responses, creating tabletop RPG battle maps, challenging traffic tickets, and contributions to physical and digital magazines. Additionally, there are releases of new datasets by Replete-AI, launches of new AI models like GPT4ALL 3.0 and InternLM-XComposer-2.5, as well as discussions on leveraging visual-semantic information for image classification, zero/few shot multi-modal models, and RAG datasets for context ingestion. Overall, the channels provide valuable insights into the evolving landscape of AI research and applications.
OpenRouter (Alex Atallah) App Showcase and General Messages
The team did an awesome job, with a member sharing a credit story during a lunch hour. Check out the Mysticella Bot for AI model interfacing, offering the first 1000 responses for free. In another chat, discussions revolved around topics such as quantization of LLM models, Microsoft API changes, Infermatic's privacy policy update, DeepSeek Coder equation issues, and criticism of Mistral Codestral API pricing. Links to UGI Leaderboard, Llama model, OpenRouter limits, Mistral AI capabilities, LLM inference guide, and more were shared.
The Eleuther discussions in various channels covered a range of topics including diffusion forcing for planning, comparison of research strategies, continual pre-training for LLMs, homotopy classes in function approximation, and more. Links to protein discovery, 1.58-bit LLMs, and research strategies were mentioned.
The ongoing discussions in the Eleuther channels also addressed the use of SAEs on Llama 3 8B, residual stream processing, a toolkit for scaling law research, and more. Links to the EleutherAI GitHub repository were provided.
Specific issues and inquiries in various Eleuther channels included preprocessing function optimization, proof-pile config errors, metric inconsistencies, model name length causing saving problems, parallel evaluation setups, multimodal challenges with SDXL latent downscaling, LangChain usage difficulties, preferences between OpenAI and ChatOpenAI, PeopleGPT in Juicebox.ai functionality, and LangChain performance concerns.
The LangChain AI general channel involved discussions on the challenges faced with LangChain usage, preferences between OpenAI and ChatOpenAI, the functionality of PeopleGPT in Juicebox.ai, and issues related to LangChain performance improvements.
Debugging and Security in Open Interpreter Community
Members of the Open Interpreter community discussed various topics related to debugging features, security measures, and community events. The implementation of a new 'wtf' command in Open Interpreter allows users to change VSC themes and debug errors in the terminal. The community also acknowledged the Open Interpreter team's dedication to security, with plans for future security roundtables. Additionally, the community celebrated the success of the 4th of July House Party event, which showcased new demos and previews of upcoming updates.
Diverse Topics on Mojo, AI Olympiads, and LLM Finetuning
The section covers discussions on various topics including Mojo bug reports, casting file pointers to structs, external program runs, and handling bitcast issues. Additionally, it highlights a proposal for a 'Mojo Fundamentals' course at EDx, with recommendations for up-to-date resources. Other sections delve into AI Mathematical Olympiad solutions, the advantages of in-context learning over fine-tuning for LLMs, and contentious claims about missing GPU credits. Another interesting topic is the iterative eval dataset building for Text2SQL and discussions on applying eval frameworks to unstructured applications, challenges faced, and gratitude towards community members. Additionally, there are talks about pushing models to HF_HUB for inference endpoints, struggles with special tokens setup, and training outcomes favoring L3 70B Instruct model over L3 8B base.
OpenAccess AI Collective (axolotl) General
build.nvidia API has hiccups: A member noted trouble with the build.nvidia API. Another pointed out the emergence of a queue system for handling requests.
Pipeline accepts YAML inputs: In a discussion on handling inputs, a member mentioned their pipeline employs YAML examples of conversations for a few-shot learning. They clarified this when questioned about incorporating textbook data.
MLOps @Chipro ▷ #events
Claude Hackathon Collaboration: A member invited others to collaborate and build something cool for the Claude hackathon. Optimize Kafka and Save Costs!: Join a webinar on July 18th at 4 PM IST to learn best practices for optimizing Kafka, including scaling strategies and cost-saving techniques. Expert Speakers at Kafka Webinar: The event will feature Yaniv Ben Hemo from Superstream and Viktor Somogyi-Vass from Cloudera, who will share their expertise on building scalable, cost-efficient Kafka environments.
FAQ
Q: What are some AI-related discussions that were recapped in this section?
A: The section provides a recap of AI-related discussions on topics such as issues with Stripe accounts, AI progress, AI models, AI safety and security, AI art and media, robotics, and various miscellaneous AI-related topics.
Q: What are some key points discussed in the AI Progress and Implications section?
A: Some key points discussed include economic impact of AI, AI-generated humor, a hacker breach at OpenAI, and major anti-aging effects seen in mice.
Q: What new AI models were introduced and their capabilities?
A: New models like Gemma 2 and nanoLLaVA-1.5 were introduced in the AI Models and Capabilities section, improving speed, performance, and introducing Reflection as a Service for LLMs.
Q: What were some of the topics discussed in the AI Safety and Security section?
A: Discussions in this section covered securing LLM apps, limitations of current AI trustworthiness, and other related safety and security concerns.
Q: What were some of the highlights in the Robotics and Embodied AI section?
A: Highlights in this section included videos of Menteebot and Japan's giant humanoid robot development, as well as a call for the development of open-source mechs.
Q: What were some interesting points discussed in the API Queue System Quirks section?
A: Issues with the build.nvidia API leading to a new queue system for managing requests were discussed, hinting at a potentially overloaded service.
Q: What was the focus of the YAML Yields Pipeline Progress section?
A: The section focused on a member sharing their pipeline's integration of YAML examples for few-shot learning conversation models, sparking interest for its application with textbook data.
Q: What were some notable discussions in the Gemma2 Garners Stability section?
A: Discussions included the Gemma2 update bringing solutions to past bugs, the importance of version control with pinned versions of transformers for smoother updates, and the role of Continuous Integration tools in catching issues preemptively.
Q: What was the main point discussed in A Call for More VRAM?
A: The succinct message highlighted the ongoing demand within the group for more VRAM, reflecting the need for higher performance computing resources.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!